Lab 4: Processing pipeline
Automate call recording processing
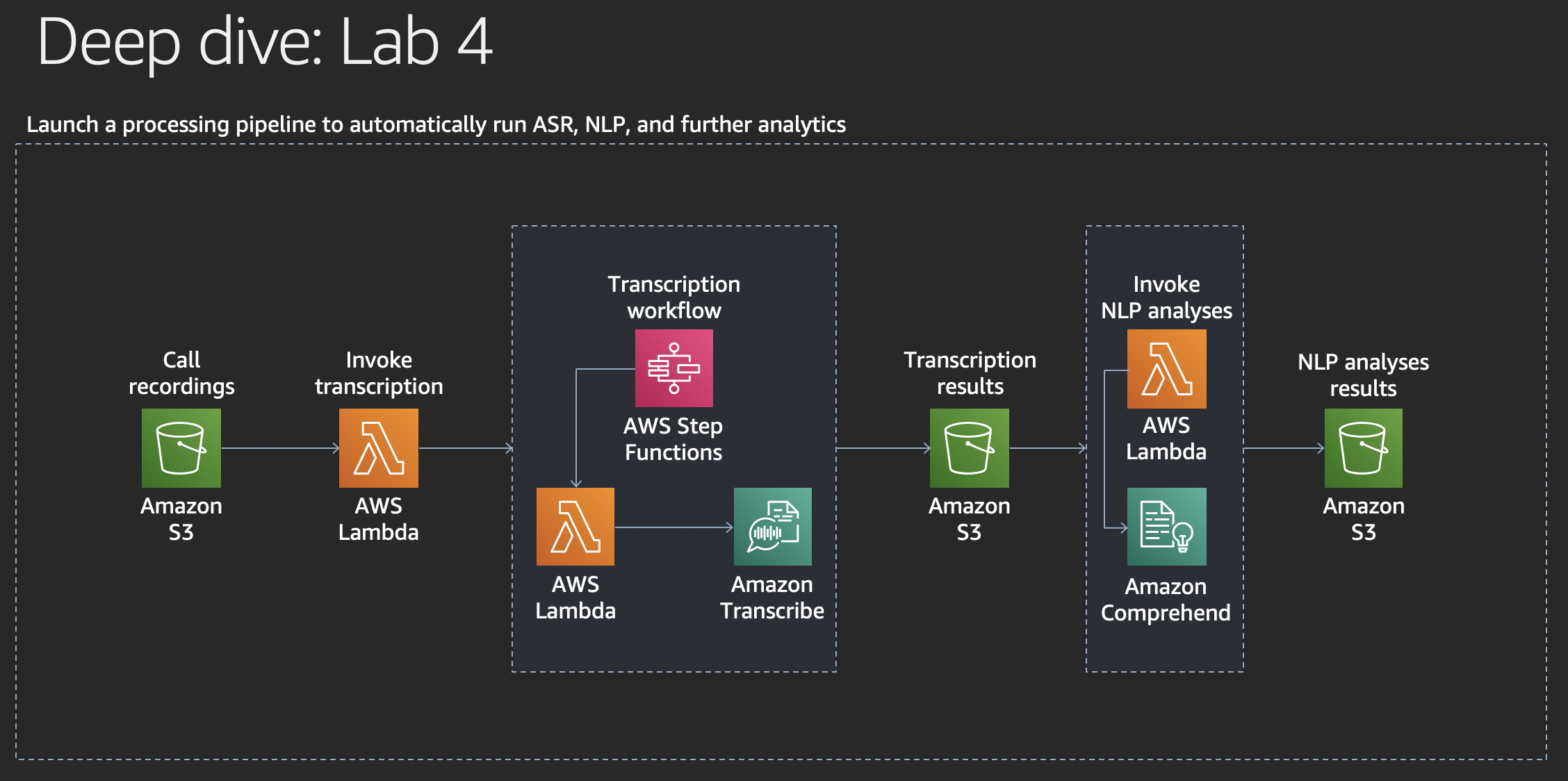
In this lab we will establish a processing pipeline that will automatically process a call recording using Amazon Transcribe for Automatic Speech Recognition (ASR) and Amazon Comprehend for Natural Language Processing (NLP).
We will not have enough time in this workshop for you to implement this yourself, so we have brought an AWS CloudFormation template that sets this up for you in a pure serverless fashion. We will explore how this is done.
The code in the processing pipeline is executed by AWS Lambda as serverless functions. Where orchestration is needed, this is done by AWS Step Functions.
All data that is involved in the processing steps is read from and stored to Amazon S3.
The architecture was already described in the presentation part of this workshop and we have put the architecture diagram above once more for your convenience.
Processing bucket
When we create the architecture for the pipeline, a new Amazon S3 bucket will be created to host all processing data: source, intermedia results, and final results. We will refer to this bucket as processing bucket.
We will copy call recordings that we have created or obtained in lab 0 into the processing bucket to trigger the pipeline. If you use Amazon Connect to produce your own call recordings, you can also reconfigure it to store the call recordings in the processing bucket once it is created and you know its name.