Process call recordings
We now want to use the pipeline to process our call recordings.
Difference between recordings from Amazon Connect and Amazon Polly
We wanted to give everybody the opportunity to choose between pairing-up and recording a real dialog using Amazon Connect, or to go with oneself and use Amazon Polly to synthesize an audio only with one participant. In order to keep the behavior in the processing pipeline the same for both ways, we have added an additional initial step for Amazon Connect call recordings: All recordings that arrive below the connect/ vrtual folder are considered as stereo files created by Amazon Connect and will be split into two new audio files, one containing the voice of the agent, one containing the voice of the customer. The result of that split will be stored in the recordings/ virtual folder and from there the transcription will take place.
Option 1: Run new calls with Amazon Connect
In case you have used Amazon Connect to create your own call recordings or you want to use it now, you can configure your Amazon Connect instance to store new call recordings in the processing bucket that was created by the AWS CloudFormation template.
Go to the Amazon Connect management console.
If you haven’t created an Amazon Connect instance, yet, and want to do it now, please follow the instructions in Lab 0 / Option 1: Amazon Connect. When you reach the
Data storagescreen, chooseCustomize settings, switch the radio button toSelect and existing S3 bucketeverywhere, select your processing bucket and disable encryption.If you already have an Amazon Connect instance, you can re-configure it to use the processing bucket now as data storage. Go to the Amazon Connect management console, select your instance and then change the settings in the
Data storageview in the same way as described in the step directly above.
Option 2: Process existing Amazon Connect call recordings
In case you have a few Amazon Connect call recordings and don’t want to create additional ones, you can start with uploading your recordings into the processing bucket.
Go to the Amazon S3 console and find the name of your processing bucket. Click on the name.
Click on the
Create folderbutton, create a virtual folder calledconnectand go to that folder (by clicking on its name).Click the
Uploadbutton and select one of your call recordings you have downloaded earlier to your laptop. Click on theNextbutton to continue, because we have to add meta-data to our upload that the processing pipeline assumes to be present.In the
Set permissionsform we leave everything as is and click theNextbutton.In the
Set propertiesform we need to do our work. Leave theStorage classsection untouched, though. Scroll down to view theMetadatasection. Click the drop down box namedHeader. We will use this to add an HTTP header to our upload request with the required meta data.Select the
x-amz-meta-header prefix. Now click into the field and typecontact-idsuch that you get the resulting header namex-amz-meta-contact-id. Enter an arbitrary value for this header in theValuefield and click theSavebutton. In the illustration below, we use the valuefoobar. Click theNextbutton.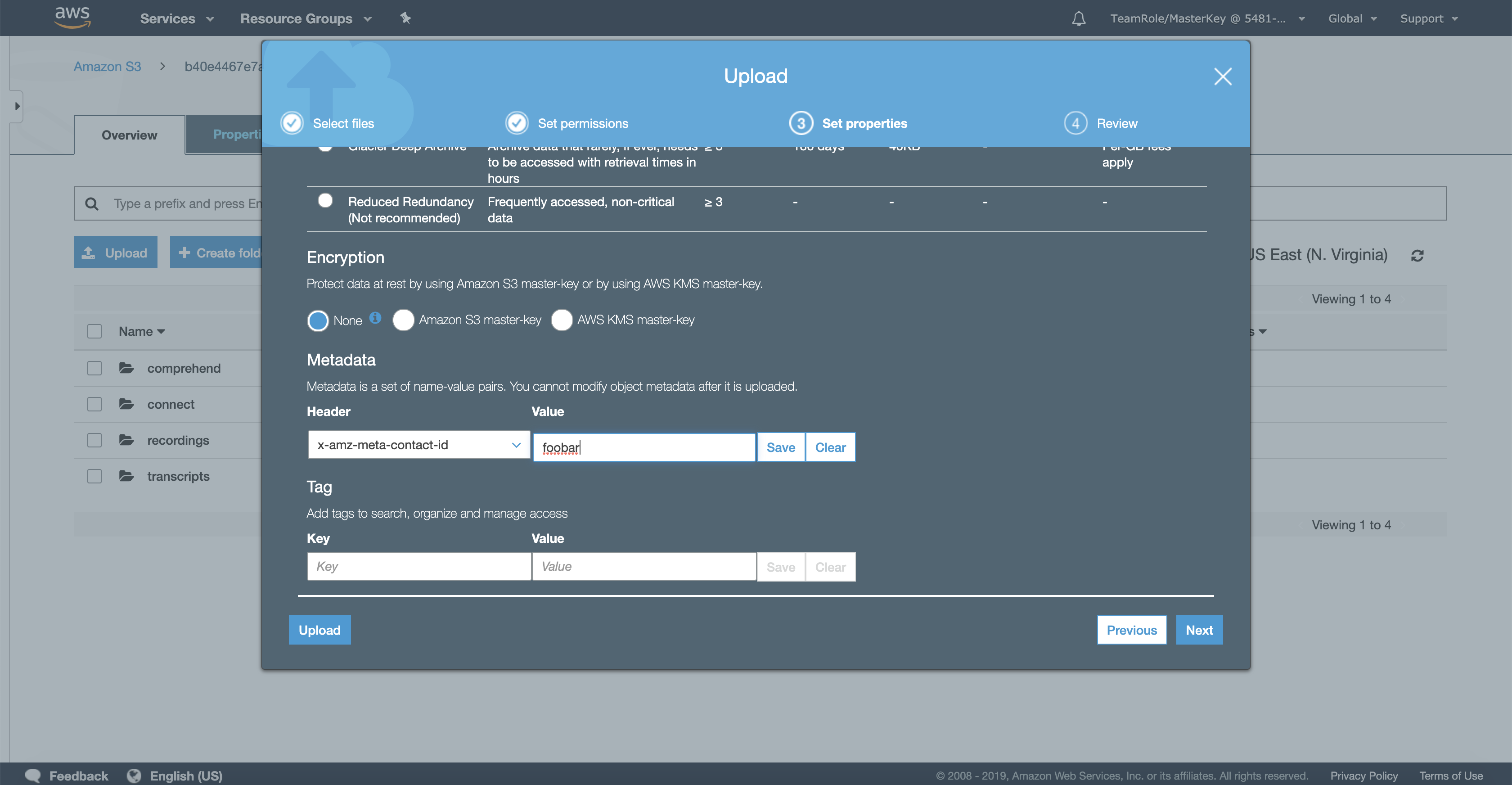
In the review form we see a summary of what we entered before. Click the
Uploadbutton to upload our recording with the provided meta information.Once the upload has succeeded, let’s pay a visit to the AWS Step Functions console. The first step in the pipeline is to split the audio file in two, one for each stero channel. However, this will already have happened very quickly and the state machine we have created in AWS Step Functions will already be triggered. In the AWS Step Functions console you will see an overview of your state machines, as long as you didn’t create one otherwise, you will only see the one created from the AWS CloudFormation stack. Click on the name of that state machine to get to the details view.
This will bring you to the details view of your state machine. Scroll down to see an overview of past and current executions in the
Executionstab. You should see two running executions, one for each of the two split audio files.Click the
Definitiontab to view the formal definition of your state machine. In the left half of this view you can see the textual definition using the Amazon States Language. This language is explained with examples in the AWS Step Functions documentation. In the right half you see the same state machine visualized as a graph, which makes it quite tangible also for non-computer-scientists. You can even create a state machine interactively by drawing such a graph. Take a moment to explore the definition of the state machine.Go back to the
Executionstab and click on the name of one of the running executions. You will get to the details view of this particular execution.Scrolling down a bit, you will see the visual workflow, showing you which steps have already been executed and which step is currently running. Take a moment to explore the details of your workflow execution.
Now that we have explored the AWS Step Functions console a bit, let’s go to the AWS Lambda console. On the first screen you will see a list of the Lambda functions in your account and currently selected AWS region. Let’s go a bit more in detail and pick one of the functions that are orchestrated by the state machine we have just observed. Click on the name of the Lambda function
submit_transcribe_job.This brings you to the details view of said Lambda function. On the right hand side you can see what other AWS services this Lambda function is entitled to access.
Scroll down a bit to see the code of this Lambda function. It’s written in Python. The code is presented in an embedded view of the AWS Cloud9 cloud IDE. Find the full size button in the top right corner of that view (marked with an orange circle in the illustration below) to get to a full size view of Cloud9.
You can explore Cloud9 a bit in the full size view. AWS Cloud9 is a cloud-based integrated development environment (IDE) that lets you write, run, and debug your code with just a browser. It includes a code editor, debugger, and terminal. Cloud9 comes prepackaged with essential tools for popular programming languages, including JavaScript, Python, PHP, and more, so you don’t need to install files or configure your development machine to start new projects. Since your Cloud9 IDE is cloud-based, you can work on your projects from your office, home, or anywhere using an internet-connected machine. Cloud9 also provides a seamless experience for developing serverless applications enabling you to easily define resources, debug, and switch between local and remote execution of serverless applications. With Cloud9, you can quickly share your development environment with your team, enabling you to pair program and track each other’s inputs in real time.
Finally, go to the Amazon S3 bucket that has been created by your AWS CloudFormation stack. That’s the one you already used to upload your call recording to in the beginning of this section. Find and click the virtual directory called
comprehend. You will find two S3 objects per call recording, one with the results of the agent channel, one with the results of the customer channel. The names of the objects will also expose thecontact-idthat was specified during your upload (and will automatically be included by Amazon Connect). The results coming out of Amazon Comprehend are in JSON format. Download one or a few of these JSON documents to your laptop and explore the content. What can you see there?
Option 3: Process existing Amazon Polly call recordings
When we want to run audio files through the pipeline that were produced by Amazon Polly,
You have decided to use Amazon Polly to produce your audio files. In this case, you have already one file per party (agent or customer) and it’s going to be MP3 files (which is default for Amazon Polly).
The processing pipeline however expects audio files as they are produced by Amazon Connect, with one stereo channel for the customer and one for the agent. This is why we will throw the Polly files directly into the recordings virtual folder in our processing bucket.
Additionally, it expects WAV files from Amazon Connect to feed into Amazon Comprehend. So, we take the opportunity and dive a bit into the respective AWS Lambda function that submits a transcription job to Amazon Comprehend. It’s fun!
As said above, to address the fact that you have already split audio files, you do not place your sample audio files in the virtual folder
connectin your source bucket, but you directly place them in the virtual folderrecordings/Agent, orrecordings/Customer, respectively. Amazon Connect would further categorize them by creation date with virtual subfolders for year, month and day of month, but that is not required to trigger the pipeline from here.To address the fact that the pipeline expects WAV files, we change the code of one of the Lambda functions. The relevant function is called
execute_transcription_state_machine. Go to the Lambda console and find this function in your list of functions. Then click on its name to go to the details page for this function.Once there, scroll a bit down until you see the code of the Lambda function. It’s written in Python and you can exchange the code right in the browser. Copy the new function code as shown below and paste it into the editor instead of the existing code. Don’t forget to hit the
Savebutton in the upper right corner.
import boto3
import os
import json
client = boto3.client('stepfunctions')
def lambda_handler(event, context):
try:
print("Incoming event: " + str(event))
s3_object = event["Records"][0]["s3"]
key = s3_object["object"]["key"]
bucket_name = s3_object["bucket"]["name"]
#print(key)
#print(os.environ['TRANSCRIBE_STATE_MACHINE_ARN'])
transcribe_state_machine_arn = os.environ['TRANSCRIBE_STATE_MACHINE_ARN']
region = os.environ['AWS_REGION']
file_uri = form_key_uri(bucket_name, key, region)
job_name = get_job_name(key)
media_format = os.environ["MEDIA_FORMAT"]
language_code = os.environ["LANGUAGE_CODE"]
print("s3_object: " + str(s3_object))
print("key: " + key)
print("bucket_name: " + bucket_name)
print("transcribe_state_machine_arn: " + transcribe_state_machine_arn)
print("region: " + region)
print("file_uri: " + file_uri)
print("job_name: " + job_name)
print("media_format: " + media_format)
print("language_code: " + language_code)
# Trying to extract media format from object key:
print("Trying to extract media format from object key:")
supported_audio_formats_list = ["mp3", "mp4", "wav", "flac"]
print("Supported audio formats: " + str(supported_audio_formats_list))
split_list = key.rsplit('.', 1)
print("Result of attempt to split file name extension from object key: " + str(split_list))
print("Size of list: " + str(len(split_list)))
if len(split_list) >= 2:
# At least the object key contained a dot.
temporary_media_format = split_list[len(split_list) - 1]
print("Extracted temporary media format from object key as: " + temporary_media_format)
# Check if that is a supported format.
if temporary_media_format in supported_audio_formats_list:
print("Temporary media format is member of supported formats.")
media_format = temporary_media_format
else:
# Falling back to environment variable settings.
print("Falling back to media format determined by environment variable settings: " + media_format)
else:
# Falling back to environment variable settings.
print("Falling back to media format determined by environment variable settings: " + media_format)
execution_input = {
"jobName": job_name,
# "mediaFormat": os.environ["MEDIA_FORMAT"],
"mediaFormat": media_format,
"fileUri": file_uri,
"languageCode": os.environ["LANGUAGE_CODE"],
"transcriptDestination": os.environ["TRANSCRIPTS_DESTINATION"],
"wait_time": os.environ["WAIT_TIME"]
}
print("Resulting execution input: " + str(execution_input))
response = client.start_execution(
stateMachineArn=os.environ['TRANSCRIBE_STATE_MACHINE_ARN'],
input=json.dumps(execution_input)
)
print(response)
return "hello"
except Exception as e:
raise e
def get_job_name(key):
key_name_without_the_file_type = key.split('.')[0]
#REMOVING FOLDERS
keys = key_name_without_the_file_type.split('/')
keys = keys[len(keys)-1].split("%") #THIS IS TO CLEAN UP CHARACTERS NOT ALLOWED BY TRANSCRIBE JOB
#GETTING THE FIRST ELEMENT
return keys[0]
def form_key_uri(bucket_name,key,region):
return "https://s3.amazonaws.com/"+bucket_name+"/"+keyNow you can upload your Polly audio into either
recordings/Agent, orrecordings/Customer. Please follow the descriptions above for processing Connect audio files.We also added a lot of debug output in the new code above. Have you heard about Amazon CloudWatch Logs? Try to find it in the AWS Management Console and seek for the log files for your Lambda functions!