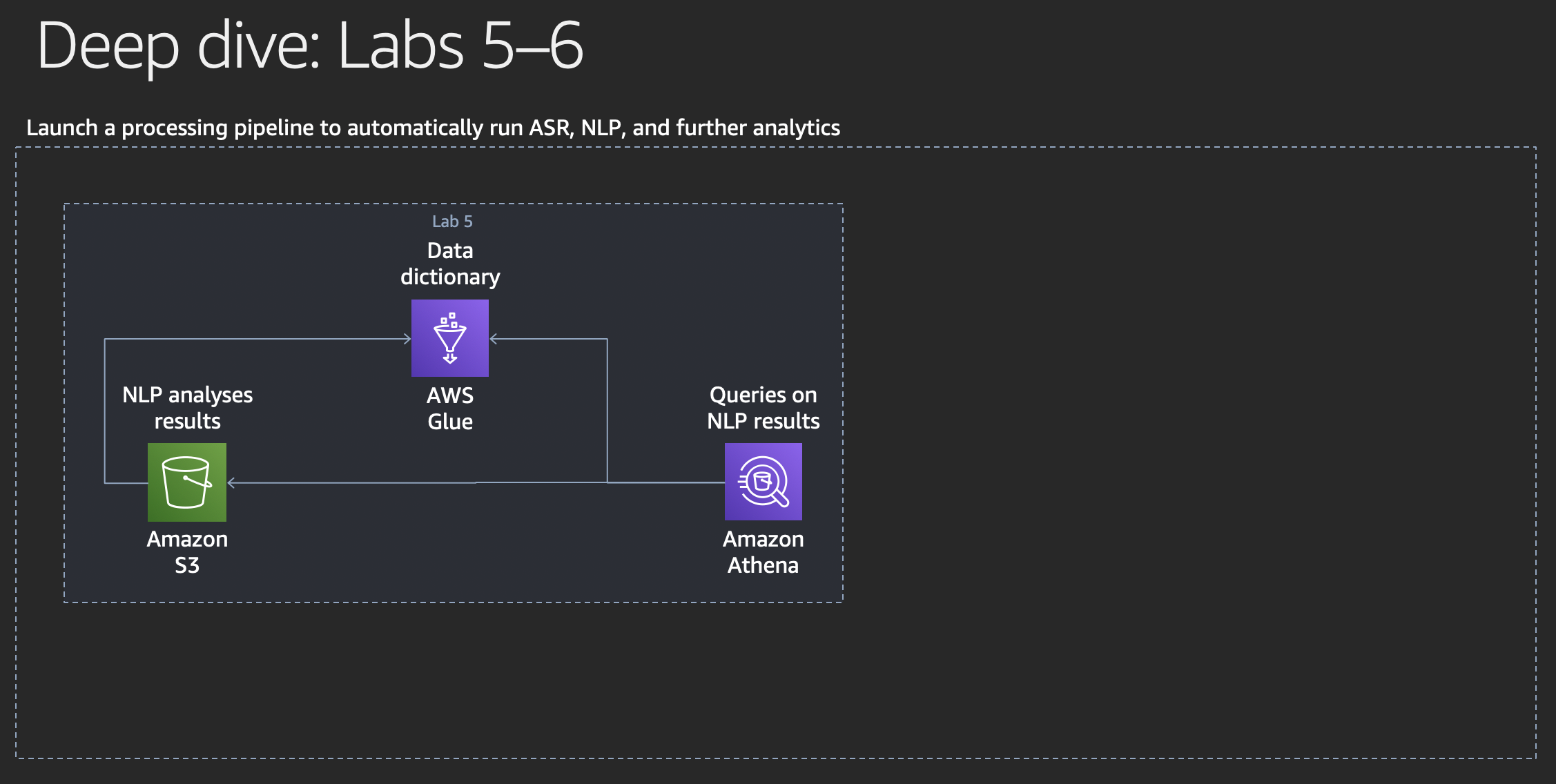
Lab 5: Amazon Athena
Query processing results
Analytics
Let’s now have a look into analytics. If you have a look at the Data Lakes and Analytics on AWS landing page, you can see that there is a broad range of options to run analytics on AWS. As always, we want to give our customers the choice to use the best tool for their job. Next to the options of using AWS services, you obviously can also run additional analytics software yourself on AWS or purchase EC2-based or SaaS solutions from the AWS Marketplace.
In this lab, we will have a look at Amazon Athena, supported by AWS Glue.
Amazon Athena and AWS Glue
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
Athena is easy to use. Simply point to your data in Amazon S3, define the schema, and start querying using standard SQL. Most results are delivered within seconds. With Athena, there’s no need for complex ETL jobs to prepare your data for analysis. This makes it easy for anyone with SQL skills to quickly analyze large-scale datasets.
Athena is out-of-the-box integrated with AWS Glue Data Catalog, allowing you to create a unified metadata repository across various services, crawl data sources to discover schemas and populate your Catalog with new and modified table and partition definitions, and maintain schema versioning. You can also use Glue’s fully-managed ETL capabilities to transform data or convert it into columnar formats to optimize cost and improve performance.
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics. You can create and run an ETL job with a few clicks in the AWS Management Console. You simply point AWS Glue to your data stored on AWS, and AWS Glue discovers your data and stores the associated metadata (e.g. table definition and schema) in the AWS Glue Data Catalog. Once cataloged, your data is immediately searchable, queryable, and available for ETL.
Running SQL queries on NLP results
We want to use Amazon Athena now to run SQL queries on the results of our sentitment analyses with Amazon Comprehend.
Go the the Amazon Athena console. If you see a splash screen, just click on the
Get Startedbutton to reach the actual console. On the left hand side you should see aData sourcenamedawsdatacatalogand below of that, aDatabasecalledcomprehendgluedatabase-.... In this database, there is a table defined already (as a result of the AWS CloudFormation template you launched in lab 4) calledsentiment_analysis.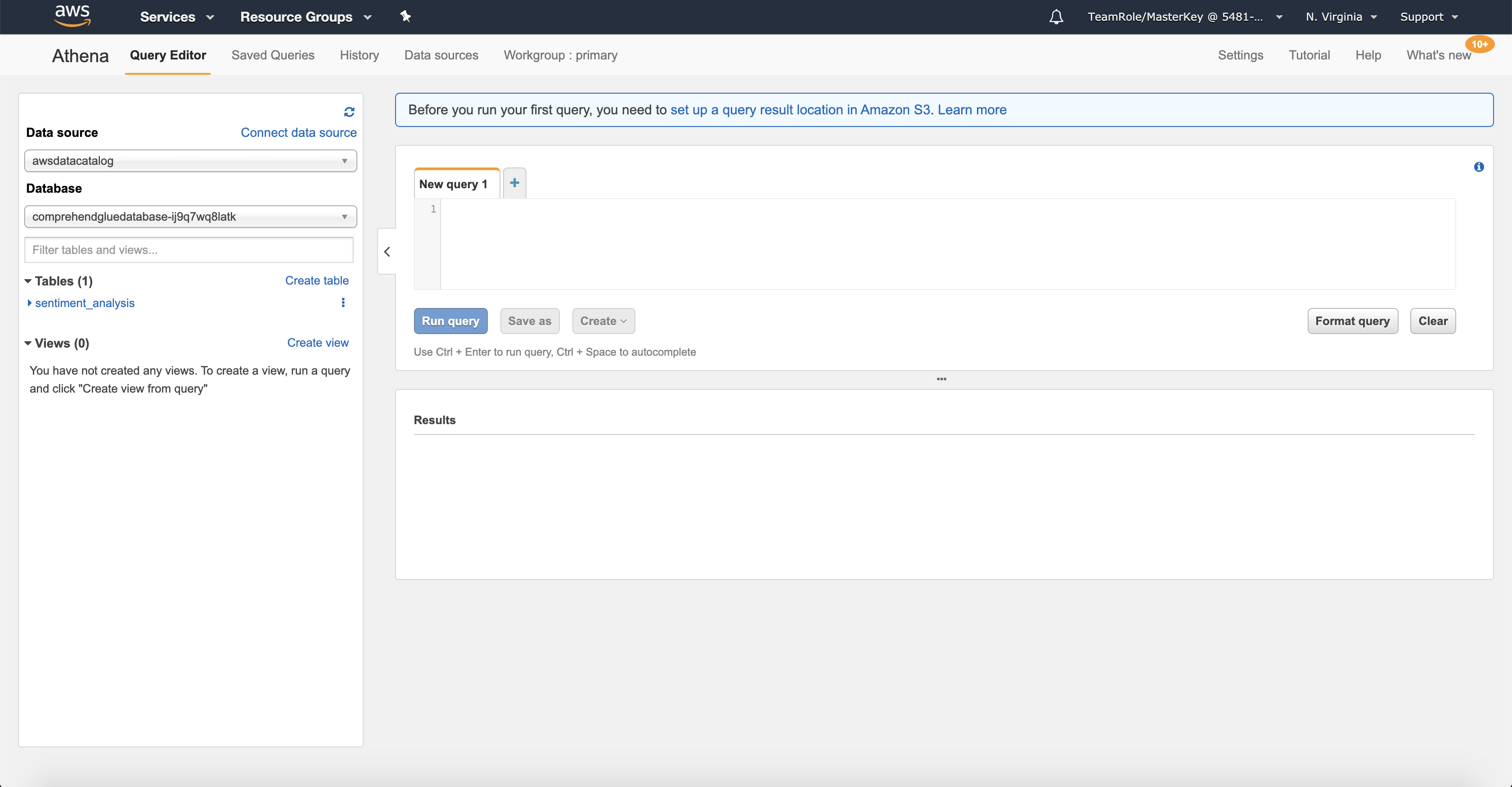
You most likely see above the query editor field in the center a hint saying:
Before you run your first query, you need to set up a query result location in Amazon S3.. Click on the link behindset up a query result location in Amazon S3to see a pop-up dialog. In theQuery result locationfield, enter an S3 URI using your processing bucket name following this pattern:s3://<processing-bucket-name>/query-results/. Also check theAutocompletecheck box. Click onSaveto continue.In the main section of the screen you can now enter SQL queries to work on your data. Remember, the data we’re talking about are the results of your Amazon Comprehend jobs that were stored in your Amazon S3 bucket. Just give it a try with retrieving all content from your virtual table - you can copy the SQL query from the code block below and paste it into the Athena console. Then click the
Run querybutton. Your query results will appear in theResultsarea below the query editor. Take a moment to explore the query results.select * from sentiment_analysis;Now click the arrowhead directly left of your table name
sentiment_analysisin the navigation section on the left of the screen. You will see a drop down list of the column names and types of your virtual table.Based on what you have seen so far about the definition and the content of your table, you can formulate a more sophisticated SQL query with projection and selection. Let’s retrieve the sentiment data only for our customer transcriptions - you can copy the query from the code block below.
select sentiment from sentiment_analysis where talker = 'Customer';
Let’s explore the Amazon Athena console a bit more. In the lower left quadrant of the screen you can see an empty list of views. Views are a well-known concept in relational databases (a pre-defined query kept in the database dictionary that users can treat like a table). Click
Create viewand you’ll see a sample view definition in the query editor.Try to create a view yourself that retrieves the sentiment values for customer transcripts only and then fire an SQL query to your view.
Now click the
Data sourceslink at the top of the Amazon Athena console. You will see a table that probably only hasawsdatacatalogas a single element. Click on that name and you should land on the AWS Glue console. If you see a splash screen, just click onGet startedto continue. You will see (at least) the tablesentiment_analysisthat you’ve just been using from Amazon Athena in the AWS Glue console.Click the
Databaseslink in the navigation area on the left to see an overview of your AWS Glue databases. There may be other databases in the list, for instance one that is calledsampledb.Click your database name and then on your table name to get to the details view for your table. In the
Locationfield you can see that the table is based on objects in your Amazon S3 bucket whose object keys start withcomprehend/. This is the virtual folder where the processing pipeline stores results from Amazon Comprehend.When you go back to the Amazon Athena console and click on
Query editor, you can retrieve the current amount of tuples in your table using the following query.select count(*) from sentiment_analysis;If you like it to be auto-formatted, you can press the
Format querybutton at the bottom right of the query editor. That will lead you to the following format:SELECT count(*) FROM sentiment_analysis;You can verify that, after a new call recording is added, the amount of tuples in your table will be +2.
Conclusion
Congratulations!
You have successfully used AWS Glue and Amazon Athena to run SQL queries on JSON documents. In general, you used AWS Glue to create a data dictionary on one of many supported kinds of data sources and used Amazon Athena to query the data in an ad-hoc manner.
In the next lab we will have a look how we can visualize these query results.